
Here is a picture of robots building a giant hard drive generated by AI, for no good reason - by Seth Jenks
Special thanks to Western Digital for sending me the drives to test and being available to answer many of my technical questions!
What is SMR?
The Chia farmer community has figured out that high-capacity HDDs deliver the lowest total cost of ownership (TCO) for Chia farming. SMR, or shingled magnetic recording, is a technology that allows for storing more data in the same physical disk. SMR uses the fact that the read heads are narrower than the write heads by physically overlapping tracks on the disks closer together (shingling) with another track of data. The end result is that you get a disk with higher track density, increased data storage capacity, a drive that can only be sequentially written, but read normally after the writes are complete. This was my first experience using an SMR drive for Chia farming that involved some tuning of the operating system and filesystem and some small workarounds (e.g. filling up the drive with plots completely before starting the harvester). These are manageable and will become even easier as the prerequisites for zone-aware storage are being made available in modern Linux kernels and filesystems by default.
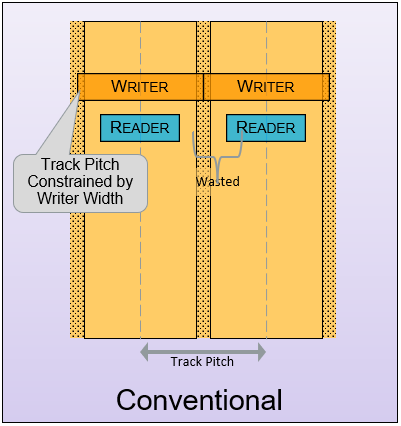
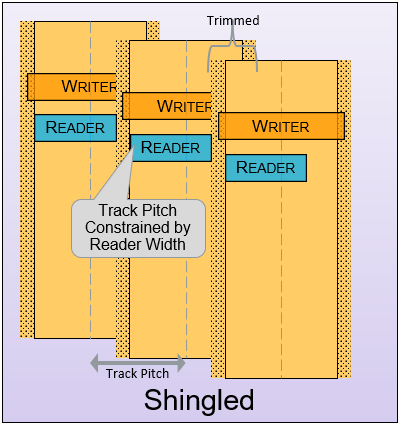
Source: Western Digital Recording Technologies Explained
WORM storage (write once, read many) describes application workloads like active archival storage and Chia farming, and are a great workload for SMR. Plot files are sequentially written to the destination drive for farming in Chia. Once the drive is full of plots, it is best practice to mount the drive as read-only to prevent the operating system from ever performing any writes on the drive.
There are two types of SMR, DM-SMR (drive managed) and HM-SMR (host-managed).
DM-SMR are typically the smaller capacity inexpensive drives for desktop backup. The drive firmware manages the rules for writing in “zones” and presents the drive normally to the operating system. DM-SMR performs poorly in workloads that include random write (as many users noted when using these in ZFS during a rebuild). There was a bit of bad press about SMR a few years back when vendors weren’t properly disclosing the type of drive being sold.
HM-SMR, which you may also hear called Zoned Storage, is a different device type with a unique command set, which restricts the host to only write according to the rules of the SMR zones. The command set enforces all writes are done sequentially to the physical media, and the host must manage the writing and data organization to ensure predictable performance. Zoned Storage drives are most typically used for large-scale datacenter applications, where the scale provides sufficient ROI for the application developer to tailor their application to these rules. However, as the software ecosystem matures, the Linux kernel and several Linux filesystems are building in support for Zoned Storage, which will open these drives to many more applications. WD has a nice whitepaper that describes SMR and zones and you can read up on SSD and HDD implementations of zoned storage at https://zonedstorage.io/

“Because of the shingled format of SMR, all data streams must be organized and written sequentially to the media. While the methods of SMR implementation may differ (see SMR Implementations section below), the data nonetheless must be written to the media sequentially. Consequently, should a particular track need to be modified or rewritten, the entire “band” of tracks (zone) must be rewritten. Because the modified data is potentially under another “shingle” of data, direct modification is not permitted, unlike traditional CMR drives. In the case of SMR, the entire row of shingles above the modified track needs to be rewritten in the process.”
The good news is that modern Linux kernels tease native support for SMR with zone-aware file systems, like btrfs. I decided to put this to the test! WD was gracious enough to send me two samples of the HC650 20TB, which is a HM-SMR device.

Linux Support For Zoned Storage
First, I upgraded my system to Ubuntu 21, as kernel 5.12 should bring in zone support for btrfs. I tried to create a filesystem…which failed. There are tons of changes in btrfs between kernel 5.12 and 5.16 in regards to zone support that I discovered in the release notes. Since btrfs is part of the kernel, upgrading it isn’t simply downloading a package or through apt or snap. You have to compile from source. After installing a boatload of dependencies, I follow the steps here to build and install.
Note: I review the details below, but after encountering a few minor issues, the recommendation going forward for using HM-SMR drives in Linux is to find a distribution with a very modern kernel (5.15+ as of writing this). Good timing on the new Ubuntu 22 LTS coming out in a few months with native support. I would not recommend compiling btrfs from source, but I’m doing it anyways - for science! Success! Btrfs version now showing v5.16 Now I create the filesystem using
$ sudo mkfs.btrfs -O zoned -d single -m single /dev/sda
btrfs-progs v5.16
See http://btrfs.wiki.kernel.org for more information.
Resetting device zones /dev/sda (74508 zones) ...
NOTE: several default settings have changed in version 5.15, please make sure
this does not affect your deployments:
- DUP for metadata (-m dup)
- enabled no-holes (-O no-holes)
- enabled free-space-tree (-R free-space-tree)
Label: (null)
UUID: 0bffb0e4-368a-4d39-a3ee-997df636632c
Node size: 16384
Sector size: 4096
Filesystem size: 18.19TiB
Block group profiles:
Data: single 256.00MiB
Metadata: single 256.00MiB
System: single 256.00MiB
SSD detected: no
Zoned device: yes
Zone size: 256.00MiB
Incompat features: extref, skinny-metadata, no-holes, zoned
Runtime features: free-space-tree
Checksum: crc32c
Number of devices: 1
Devices:
ID SIZE PATH
1 18.19TiB /dev/sda
Filling up the drive with plots
Next I run a script that uses rsync to copy the plots from another server to this one. It takes about 29 hours to fill up both drives, writing to each as fast as they can go

Oddly, Prometheus/Nodexporter/Grafana show an incorrect scale for the IO (WD would be selling a whole lot of these hard drives if they could indeed write this fast!!). The file copy of 20TB of plots completed after 29 hours, suggesting that the drive’s average bandwidth (which you see starts out higher) was around 190MB/s, which is more accurate.
iostat -h -t 10 /dev/sda
Is showing 218MB/s at the beginning of the transfer
and dstat is showing about 450MB/s (or 225 per drive)

Start the harvester
When the drives are a little over 90%, I fire up Chia and add the drives as farming destinations. I check the harvester log, to see what the IO looks like
cat ~/.chia/mainnet/log/debug.log | grep elig
2022-02-11T02:18:53.371 harvester chia.harvester.harvester: INFO 2 plots were eligible for farming 4b3551e142... Found 0 proofs. Time: 104.58837 s. Total 354 plots
2022-02-11T02:19:17.270 harvester chia.harvester.harvester: INFO 0 plots were eligible for farming 4b3551e142... Found 0 proofs. Time: 0.02066 s. Total 356 plots
2022-02-11T02:19:19.393 harvester chia.harvester.harvester: INFO 2 plots were eligible for farming 4b3551e142... Found 0 proofs. Time: 21.75540 s. Total 356 plots
2022-02-11T02:19:46.705 harvester chia.harvester.harvester: INFO 2 plots were eligible for farming 4b3551e142... Found 0 proofs. Time: 39.33693 s. Total 356 plots
2022-02-11T02:19:49.368 harvester chia.harvester.harvester: INFO 1 plots were eligible for farming 5eda2fcbf3... Found 0 proofs. Time: 161.00288 s. Total 356 plots
No bueno…we are seeing harvester latency spikes of up to 161 seconds. What appears to be happening is the read requests are getting stuck behind a ton of write requests, which does happen when you try to do random reads while writing the maximum bandwidth. I did not mess with the scheduler on this, which after reading the zone documentation, suggests the use of the mq-deadline scheduler for btrfs with zones. Typically, if a farmer is copying the final plots to a drive on a CMR drive while farming, the scheduler needs to be changed to bfq to prioritize the reads over the write commands in the queue, and thus optimize the harvester read latency.
This was a little confusing to me, since grafana is only reporting a max read latency of a few seconds on the disk. A proof quality check for plots that pass the filter takes on average 9 lookups in the plot tables, and generally, that corresponds to 9 random read requests per plot file that passes the filter. The harvester latency reports the cumulative latency for every signage point.

It is also possible the latency is getting stuck somewhere higher up the stack, since the zones introduce a new layer in the kernel stack, and also possible the software reads aren’t optimized for Chia farming in btrfs with the default zone settings.
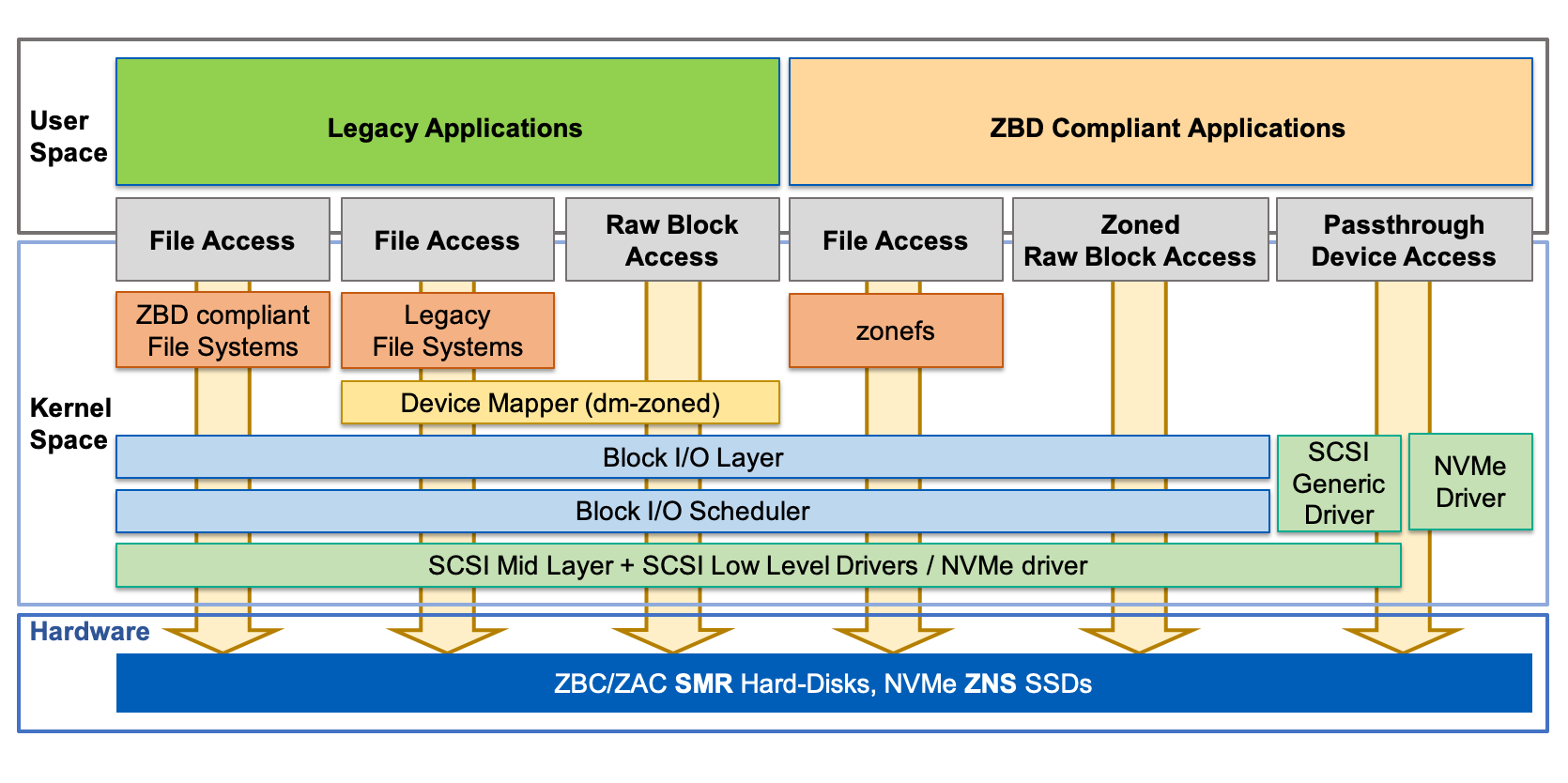
Source: ZonedStorage.io
Note: after talking to some experts, what I’m hitting may be fixed in this commit to block-mq (meaning I need the full kernel 5.15+ not just btrfs updated, since block-mq is deeply embedded in the kernel for storage functionality) (“block: schedule queue restart after BLK_STS_ZONE_RESOURCE”), which fixes a blocking of IOs for a long time, around 30 seconds.
The workaround on my system was to wait until the drive is full before adding the drive to the harvester. This may not seem practical at first, but when you expect to farm for 5-7 years, waiting 29 hours for the drives to fill up isn’t a big deal. This does require that you fill up one drive at a time with plots instead of evenly distributing the plots across the entire farm.
After the drives are 100% full, I unmount, and then mount again with the -o ro flag, as writes are no longer required for farming. This is the scary part. Because the drives are full of data, and all in zones, the btrfs mount takes a VERY long time, around 3-5 minutes per drive. I was in full panic mode…however, they finally mounted. I’m hoping the reason for the long mount was due to the blocking IO bug mentioned earlier, which I will have to retest when I get a chance.
df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda 19T 19T 51G 100% /mnt/hdd1
/dev/sdb 19T 19T 52G 100% /mnt/hdd2
mount
/dev/sda on /mnt/hdd1 type btrfs (ro,relatime,space_cache=v2,subvolid=5,subvol=/)
/dev/sdb on /mnt/hdd2 type btrfs (ro,relatime,space_cache=v2,subvolid=5,subvol=/
Now I started the Chia harvester service only and let it run overnight
chia start harvester
We are happily farming! I check the harvester latency with this command and graph the output
cat ~/.chia/mainnet/log/debug.log | grep elig| awk '{print $1,$16}'`
 Which is a little easier to see in a histogram format
Which is a little easier to see in a histogram format
 So we did have 228 instances of harvester latency in this around 12 hour period that were between 0.54-1.81 seconds. This is still perfectly acceptable in Chia farming, as the farmer has about 28 seconds to get a full proof of space broadcasted to the network to earn farming rewards. With the current harvester code, the harvester latency increases linearly with the number of plots passing the filter, as the harvester latency reports the sum of the time of all the proof quality checks. The disk read latency does look normal from grafana at 5.7ms per read request.
So we did have 228 instances of harvester latency in this around 12 hour period that were between 0.54-1.81 seconds. This is still perfectly acceptable in Chia farming, as the farmer has about 28 seconds to get a full proof of space broadcasted to the network to earn farming rewards. With the current harvester code, the harvester latency increases linearly with the number of plots passing the filter, as the harvester latency reports the sum of the time of all the proof quality checks. The disk read latency does look normal from grafana at 5.7ms per read request.

In a future version of the Chia harvester that is in development currently, this should be less of an issue. I will have to upgrade the harvester code and check that in a follow up.
There are definitely some differences in the amount of drive bandwidth compared to running the Chia harvester on a CMR drive. I am noticing much larger block sizes on the request in the range of 40-50kB (as compared to 12-16kB for a normal HDD). The model for Chia farming io is detailed in the Chia storage farming workload analysis. Also possible, there is also some weird interaction with 4k native sector size and btrfs, which we can design a few short experiments to rule out. There is always room for tuning and settings for optimal disk use in Chia farming, but my short experiment showed that farming off HM-SMR most certainly works. When Linux distributions start rolling out with kernel 5.15, the btrfs with zone-aware drives like SMR should work out of the box. Even though zone support existed in the kernel far before that, it takes a few versions of the kernel to get fully stable, get broad compatibility, and reduce the bug count.
Summary
My first experience with HM-SMR came with a lot of learning in a short amount of time, but I’m happy to report that this will be an exciting technology for Chia farming. I won’t get into speculating about vendor pricing, but you can imagine that if you get 10-20% extra capacity on the same physical disk that the total cost of ownership is going to improve in CapEx for the drive cost as well as better power efficiency in TB/W. HM-SMR is all around a great fit for Chia farming, especially when combined with second use storage as hyperscalers using their earlier generations of SMR replace their drives with newer and higher capacity drives. I expect the HM-SMR drives released towards the end of the year will have a 30% TCO advantage vs. 18TB that are widely deployed today, an excellent advancement for HDD areal density while we wait for other technologies like HAMR/MARM to enter mass production. I can’t wait to do a follow-up to this post in the future with NVMe ZNS, which uses zones for SSDs to reduce spare area and overprovisioning on capacity-optimized SSDs.